
Observability Is the New CX Superpower — What Media & Entertainment Leaders Must Do Now
You can’t fix what you can’t see.
That old line feels truer in Media & Entertainment today. Viewers abandon a stream after one freeze. Ad revenue evaporates in minutes. Brand trust frays fast. The stakes are painfully real. New research from the New Relic 2025 Observability Forecast for Media & Entertainment makes that clear. It shows observability is no longer optional. It’s central to delivering great customer and employee experiences.
This article walks through what M&E leaders told New Relic. Then it translates those findings into practical CX and EX playbooks. Expect crisp analysis, relevant data points, and hands-on recommendations.
Why observability now equals customer experience
Media companies sell attention. Every millisecond matters.
The report finds outages often cost millions per hour. In fact, many respondents report damages of roughly $2 million per hour. That’s revenue at risk, and it heightens churn and reputational damage.
Observability connects technical telemetry to business outcomes. It shows how a spike in API latency wipes out sign-ups. It links ad delivery issues to lower CPMs. That business context is what makes observability a CX lever, not just an engineering tool.
The pressure points: complexity, spikes, and tool sprawl
Three realities complicate delivery:
- Cloud-native microservices multiply failure points.
- Live events create unpredictable traffic surges.
- Organizations juggle multiple monitoring tools.
According to the report, the median M&E org runs four observability tools. Yet nearly one in five uses eight or more. That fragmentation slows root-cause work and hurts cross-team collaboration. Conversely, 40% now run three or fewer tools, signaling consolidation momentum.
Primary outage causes also reveal focus areas. Security failures topped the list at about 40%. Network failure and capacity constraints followed. Deployment errors and third-party failures also appear often. These are operational blind spots with direct CX consequences.
AI and observability: twin engines for personalization and reliability
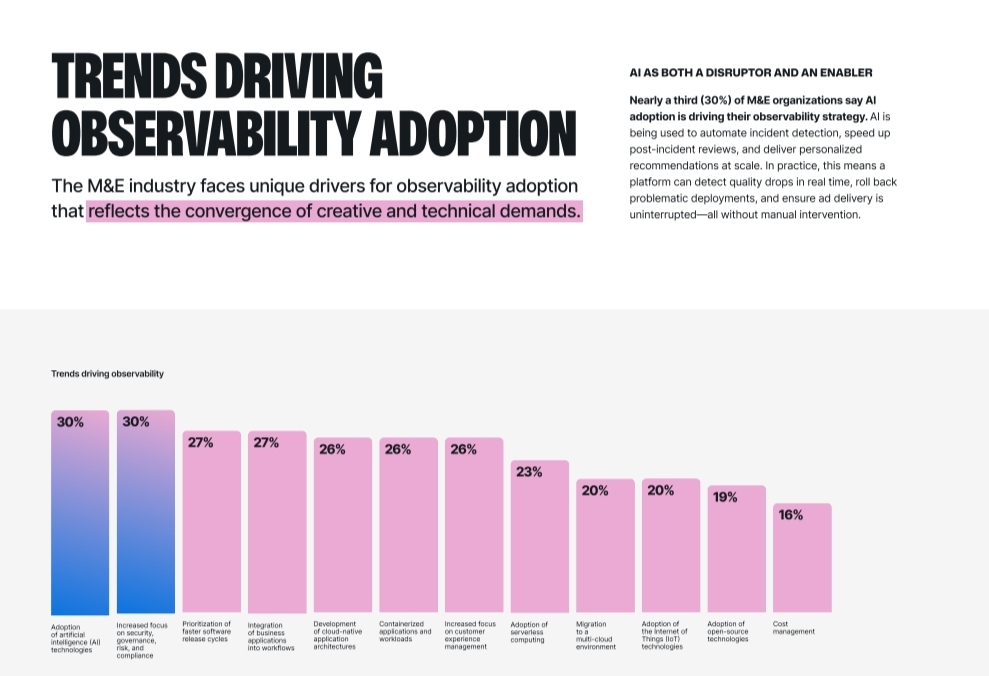
AI adoption is one of the top drivers of observability in M&E. Roughly 30% of respondents cited AI as a major driver. They use AI for automated incident detection, smarter post-incident reviews, and for personalizing recommendations at scale. Observability provides the telemetry AI needs to be safe, performant, and transparent.
But AI increases complexity. Models add new failure modes. Observability must expand to include AI telemetry. Track model drift, data pipeline health, inference latency, and feedback loops. Without those signals, personalization risks degrade CX quietly and quickly.
The ROI is real — and measurable
Here’s the hard business truth: observability pays back. Over half the M&E respondents report a two-to-three-times return on observability spend. Another large portion saw one-to-two-times ROI. Only a tiny share reported no return. That’s a powerful validation.
Where does the ROI come from? Three levers:
- Reduced outage costs. Preventing a single hour-long outage during a global event can offset the annual cost of an observability platform.
- Better ad performance. Correlating telemetry with ad metrics keeps inventory valuable.
- Improved subscriber retention. Faster detection and remediation preserve the experience that reduces churn.
These outcomes move observability from technical line-item to strategic growth driver.
What top-performing organizations do differently
The report highlights outcomes that separate leaders from followers. Leading organizations report better uptime, stronger operational efficiency, and tangible business growth tied to observability. Here’s how they operate.
- Integrate business and technical data.
Top teams don’t monitor systems in isolation. They map telemetry to customer and marketing KPIs. This lets them quantify the business impact of technical issues. - Consolidate where it counts.
Fewer fragmented dashboards means faster cross-team troubleshooting. Leaders favor unified platforms that pair full-stack telemetry with business context. - Instrument for live operations.
They build playbooks for known live-event failure modes. They run load rehearsals and validate CDN and ad-path resilience. - Embed AI observability.
Teams instrument model inputs, outputs, and inference latency. This visibility prevents personalization failures from becoming CX crises. - Measure MTTD and MTTR.
Median detection and resolution times in M&E hover around 30 and 40 minutes respectively. Leaders push both down with automation and runbooks.
Practical CX/EX playbook: how to act this quarter
Below are concrete steps CX and EX teams can implement now. Each recommendation ties to a clear business outcome.
1. Map technical signals to CX metrics
Inventory your core CX journeys. Link telemetry to conversion, churn, and ad metrics.
Outcome: Prioritized alerts that reflect business impact.
2. Consolidate monitoring tooling
Audit your toolset. Eliminate redundant dashboards. Consolidate to a platform that supports full-stack visibility.
Outcome: Faster incident triage and less context switching.
3. Instrument the ad delivery chain
Trace ad insertions end-to-end. Capture latency, failures, and viewability metrics. Correlate them to CPM fluctuations.
Outcome: Maximized monetization and fewer missed impressions.
4. Add AI observability today
Log model feature distributions, inference times, and prediction confidence. Hook model alerts into incident channels.
Outcome: Safer personalization and fewer silent quality degradations.
5. Run live-event chaos drills
Simulate live spikes, CDN failures, and sudden ad-load increases. Test rollback and circuit-breaker behavior.
Outcome: Reduced downtime risk during high-value events.
6. Tighten security telemetry
Increase visibility into traffic anomalies and credential misuse. Integrate security telemetry with SRE workflows.
Outcome: Lower risk of DDoS or breach-induced outages.
7. Measure ROI and report it up
Quantify downtime avoidance, ad-revenue protection, and retention gains. Report those metrics to leadership.
Outcome: Sustained budget support for observability investments.
People and process: the other half of the equation
Tools cannot substitute for well-designed processes. Observability shines only with strong human workflows. Focus on three areas.
- Cross-functional runbooks. Create runbooks that include product, SRE, security, and ad ops. Keep them living documents.
- Blameless postmortems. Use telemetry to make post-incident reviews factual and constructive.
- Shift-left observability. Embed observability checks in CI/CD pipelines. Catch regressions before they reach production.
These practices shorten mean-time-to-detect and mean-time-to-resolve. They also improve employee experience by removing firefights and unclear ownership.
Leadership questions to ask this week
CX and EX leaders should ask these targeted questions.
- Can we quantify how latency affects conversion and retention?
- How many observability tools are in active use today? Are any redundant?
- Are our AI models instrumented for production health and fairness?
- Have we rehearsed failure scenarios for our next big live event?
- What is our current MTTD and MTTR for critical services?
Answering these reveals where to prioritize investment.
Quick case: what a live-event outage looks like (and how observability prevents it)
Imagine a global sports final. Traffic triples in minutes. Ads must insert cleanly across geographies. One CDN tier fails. Without unified telemetry, teams scramble. Detection takes too long. Revenue and reputation suffer.
With a unified observability platform, the system auto-detects the CDN failure. It triggers a traffic failover. Ads reroute. Engineers see failover telemetry and validate ad-path integrity. Downtime shrinks from tens of minutes to under a minute. The audience stays, and ads remain monetized.
This is not hypothetical. The patterns and frequency of such incidents were central findings in the New Relic 2025 M&E survey. Observability proves its payback in these moments.
Measurable KPIs to adopt
Adopt a focused KPI set to track observability’s business value.
- MTTD and MTTR for top customer-impact services.
- Downtime cost avoided per quarter.
- Ad fill and CPM variance correlated to system health.
- Subscriber churn rate following incidents.
- Percentage of alerts with business-context tags.
Track these monthly and present them to the executive team.
Final recommendations — practical and prioritized
- Start with business mapping. Link your top three customer journeys to telemetry.
- Consolidate tooling where it reduces context switches. Aim for three or fewer core tools.
- Instrument AI and ad-tech today. These are high-risk, high-reward domains.
- Run chaos rehearsals quarterly. Make live-event readiness routine.
- Report ROI in revenue terms. Show how observability prevents millions lost.
Each step lowers downtime risk and strengthens both CX and EX.
Closing: observability as a strategic advantage
Media and Entertainment companies compete on experience. Observability is the infrastructure that protects and enhances that experience. The New Relic 2025 Observability Forecast makes the choice clear. Invest in unified telemetry, tie it to business metrics, and embed observability into product and operations workflows. Do that, and you turn reliability into a competitive advantage.