In an era where enterprise agility and automation define competitive advantage, seamless infrastructure orchestration has become a cornerstone of superior Customer Experience (CX). VergeIO, widely recognized as the VMware alternative built upon a unified codebase, is fast reshaping that narrative. Its latest addition — support for HashiCorp Packer and Ansible — completes a true end-to-end infrastructure automation chain, enabling organizations to build, provision, configure, and monitor infrastructure with unprecedented consistency.
What makes this stride significant is not only the technical mastery but the CX impact it channels. As customers demand frictionless digital journeys and real-time responsiveness, IT teams must deliver environments that behave predictably under any scale or circumstance. The VergeOS automation chain synchronizes the full lifecycle of infrastructure — turning repetitive tasks into coded precision and transforming complexity into control.
To dive deeper into this evolution, CXQuest sat down with Yan Ness, CEO of VergeIO, and Jason Yaeger, SVP of Engineering, to explore how this release strengthens enterprise and CSP automation journeys, simplifies VMware exit paths, and ultimately uplifts the quality and reliability of customer experience in the age of infrastructure-as-code.
Welcome, Yan Ness, CEO of VergeIO, and Jason Yaeger, SVP of Engineering
Q1. Yan, VergeIO has been positioning itself as a unified alternative to VMware. How does this latest release mark a new chapter in that transformation story?
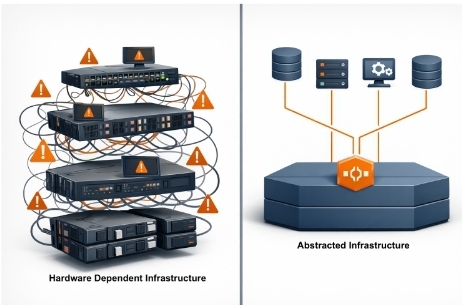
Yan Ness: This release addresses what we consistently hear from organizations evaluating VMware alternatives: they need infrastructure that makes automation work reliably, not just a different hypervisor. Most VMware exits preserve the three-tier architecture that created automation problems in the first place.
With Packer and Ansible support, organizations can now build golden images, provision infrastructure with Terraform, configure systems with Ansible, and monitor through Prometheus—all interacting with one unified API. This eliminates the fragmentation that forces teams to maintain multiple automation branches for different storage vendors and equipment generations. VergeOS replaces VMware AND simplifies the infrastructure underneath it. One transition solves both problems.
How VergeOS Presents Consistent Interfaces
Q2. Jason, could you take us through the journey behind integrating Packer and Ansible support within VergeOS?
Jason Yaeger: The journey started with a fundamental principle: abstract hardware complexity from automation tools completely. Traditional infrastructure exposes storage array details and firmware variations directly to automation code, creating brittle pipelines that break during hardware refresh.
We designed VergeOS to present consistent interfaces regardless of underlying hardware. Packer builds one golden image that works across all deployments—whether running on new NVMe drives or seven-year-old SATA SSDs. Templates don’t need storage-backend-specific drivers because VergeOS maintains consistent presentation.
Ansible integration followed the same philosophy. Playbooks reference infrastructure services through stable APIs rather than detecting hardware and branching accordingly. The result is configuration that works identically across all environments without conditional logic. Our virtual data center architecture encapsulates compute, storage, networking, and protection as single objects, ensuring automation manipulates complete environments rather than coordinating separate components.
What Specific Customer Pain Points Are Solved
Q3. Many enterprises struggle with infrastructure drift and configuration inconsistencies. What specific customer pain points were you aiming to solve with this end-to-end automation chain?
Yan Ness: The pain points cluster around organizations spending more time maintaining automation than they save through automation.
First is the multi-variant problem. Teams maintain separate Packer templates for different storage backends, separate Terraform modules for different vendors. Hardware refresh breaks everything. Weeks pass fixing automation that should have remained stable.
Second is DR unreliability. Production and DR sites run different hardware, forcing location-specific automation code. Configuration drift becomes inevitable. DR testing becomes debugging rather than validation.
Third is the test environment gap. Test infrastructure uses different equipment than production, so automation produces different results. Deployment surprises happen because environments can’t maintain consistency.
The end-to-end automation chain eliminates hardware variables. One Packer template works everywhere. Terraform modules stay unchanged during refresh. Test environments mirror production perfectly.
How to Accelerate the Entire Value Delivery Chain?
Q4. How does this shift support the growing alignment between platform engineering and customer experience priorities?
Yan Ness: Platform engineering exists to abstract complexity from application teams. But when platforms are built on fragmented infrastructure, that complexity gets pushed to platform teams. They maintain separate provisioning paths for different storage types and explain why identical code behaves differently in test and production environments.
Unified infrastructure changes this completely. Platform teams build golden images once, write Terraform modules that work across all environments, and provide self-service portals backed by reliable automation. Application teams get consistent infrastructure that responds predictably, enabling faster iteration and deployment velocity.
The customer experience connection is direct: when platform engineering removes infrastructure friction, application teams ship features faster and maintain higher service reliability. Infrastructure abstraction accelerates the entire value delivery chain.
How this Collaboration Delivers a Predictable Automation Flow?
Q5. The inclusion of Packer, Terraform, Ansible, and Prometheus sounds like an orchestration symphony. How do these components collaborate within VergeOS to deliver a predictable automation flow?
Jason Yaeger: Each tool has a distinct role but they all play through the same unified API.
Packer builds golden images by launching temporary VMs, provisioning them with Ansible, and then capturing the configured state. Images work across all deployments because we maintain consistent guest interfaces.
Terraform provisions infrastructure using those images. A single resource block defines a complete VDC. VergeOS translates service-level definitions into hardware-specific configurations for whatever equipment exists.
Ansible handles final-mile configuration. Because VergeOS provides consistent services, playbooks don’t need hardware-detection logic. The same playbook works identically everywhere.
Prometheus monitors everything through unified metrics. Storage capacity, compute utilization, and network throughput—all exposed through consistent structures. Grafana dashboards display identical hierarchies across all infrastructure.
The predictability comes from architectural abstraction. Each tool interacts with VergeOS services rather than specific hardware. When hardware changes, automation continues working.
How to Transition Your VMware-based Environments to VergeOS?
Q6. Could you elaborate on how organizations can transition their VMware-based environments to VergeOS using this automation framework?
Jason Yaeger: The transition follows a lift-and-improve pattern.
Phase one is image creation. Teams rebuild VMware templates with Packer targeting VergeOS, eliminating hardware-specific cruft. VergeOS presents standard virtio interfaces, making images simpler and more portable.
Phase two is infrastructure-as-code development. Organizations translate provisioning into Terraform modules that define VergeOS virtual data centers. VMware environments have separate automation for compute, storage, and networking. VergeOS consolidates this into unified VDC definitions.
Phase three is parallel operation. Organizations deploy VergeOS alongside VMware, replicating workloads while testing automation pipelines. This proves automation works reliably before full migration.
Phase four is production cutover. Workloads migrate permanently. Former VMware infrastructure becomes DR capacity or retires entirely. Organizations often eliminate storage arrays—they become unnecessary when VergeOS uses commodity SSDs.
The framework supports this transition because Packer, Terraform, and Ansible work consistently throughout. Automation skills developed during migration continue delivering value post-migration.
How Automation Impacts Uptime, Consistency, and Responsiveness
Q7. Automation efficiency undoubtedly affects uptime, consistency, and responsiveness — all of which define modern CX. How are your customers experiencing these benefits so far?
Yan Ness: We’re seeing impact across multiple dimensions.
An insurance company cut DR test time from eight hours to thirty minutes. Previously, tests involved manual debugging. Now the same pipeline executes identically, and tests validate business continuity rather than infrastructure code compatibility.
A healthcare provider eliminated three weeks from their deployment cycle. They were maintaining separate Packer templates for production, DR, and test due to hardware differences. With unified infrastructure, one template works everywhere. Clinical applications reach users more rapidly.
A managed service provider gained the ability to offer infrastructure-as-code to mid-market customers. Previously, automation maintenance overhead only justified enterprise-tier customers. VergeOS automation stability changed the economics.
The uptime impact comes from eliminating human error during infrastructure changes. When automation works reliably, teams trust it and stop falling back to manual procedures during pressure situations. Manual procedures are where mistakes happen.
How Infrastructure-as-code Empowers CX Leaders?
Q8. In your view, how does infrastructure-as-code empower CX leaders beyond IT — perhaps even influencing the way product or service experiences are delivered?
Yan Ness: Infrastructure-as-code changes the fundamental constraint on innovation velocity. Traditionally, IT infrastructure was a fixed constraint that product and CX teams worked around. Infrastructure became a bottleneck.
When infrastructure-as-code works reliably, product teams gain agency. They provision test environments, experiment with architectures, and iterate rapidly without waiting for infrastructure approvals. A/B testing becomes practical because spinning up isolated environments is automated rather than a multi-week project.
This shifts how CX leaders think about service delivery. Instead of planning around infrastructure limitations, they plan around customer needs and use automation to materialize required infrastructure.
We’re also seeing CX teams use infrastructure automation for resilience that directly affects customer experience. Geographic distribution becomes straightforward. Disaster recovery becomes reliable. Customers experience better availability because consistent automation enables operational practices that weren’t previously feasible.
How it Simplifies Operational CX?
Q9. Cloud service providers often face multi-tenant consistency and provisioning bottlenecks. How does this update simplify their operational CX?
Jason Yaeger: Multi-tenant environments magnify every infrastructure inconsistency. Service providers running traditional infrastructure maintain different provisioning paths based on which storage arrays have capacity and which hardware generation hosts the workload. Customer environments drift, troubleshooting becomes nightmare.
VergeOS virtual data centers solve this through complete encapsulation. Each customer gets a VDC containing their compute, storage, networking, and protection as a single object. Provisioning is identical regardless of underlying hardware. A customer VDC on seven-year-old servers behaves identically to one on new equipment.
This improves operational CX dramatically. Provisioning becomes fast and predictable. Capacity management simplifies because service providers can utilize hardware fully without worrying that older equipment creates experience differences. Troubleshooting becomes tractable because customer environments are truly isolated.
The update enables service providers to deliver infrastructure-as-a-service that actually behaves like code—predictable, repeatable, and reliable.
Understand the Power of Unified Platforms
Q10. Where do you see VergeIO positioned in 2026 vis-à-vis the evolving VMware exit landscape and the demand for unified automation?
Yan Ness: 2026 is when VMware exit decisions made in 2024 and 2025 show their operational consequences. Organizations that swapped hypervisors while preserving three-tier architecture are discovering they still have automation problems. The hypervisor vendor changed, but the underlying fragmentation persists.
We’re positioned as the alternative that actually solves the infrastructure problem. Our differentiation is architectural: we eliminated external storage arrays in favor of commodity SSDs while maintaining enterprise capabilities. We integrated storage, compute, and networking into a single operating system with a single API.
The market is discovering that “VMware alternative” isn’t the correct framing. The real question is whether you want infrastructure that supports reliable automation or infrastructure that fights it. By 2026, we expect to be known as the infrastructure operating system that makes automation work. Organizations that chose unified platforms will be outpacing competitors, still debugging infrastructure-specific automation issues.
What After Full Lifecycle Becomes Mainstream?
Q11. As full lifecycle automation becomes mainstream, what’s next for VergeIO’s product roadmap?
Yan Ness: We’re focused on deepening abstraction while expanding infrastructure services exposed through our unified API. The pattern is consistent: identify operational complexity that forces workarounds in fragmented infrastructure, then integrate it as a native service.
In the near term, we’re enhancing support for AI infrastructure. Organizations building private AI deployments are maintaining two fragmented environments: traditional workloads and AI workloads running on GPU clusters. That doubles automation complexity. We’re integrating AI infrastructure as another workload type managed through the same unified approach.
We’re also expanding edge capabilities. Organizations want to deploy infrastructure at remote locations using identical automation. VergeOS abstraction solves this—the same automation deploys applications identically whether running on data center servers or edge appliances.
In the long term, we’re exploring how infrastructure intelligence can inform automation decisions. Can the infrastructure operating system suggest optimizations based on actual workload behavior? Can it predict when automation will fail due to capacity constraints before failure occurs? These are areas where unified infrastructure has visibility that fragmented systems cannot achieve.
What’s the Future of CX Automation?
Q12. In three words, how would you describe the future of CX automation from an infrastructure intelligence standpoint?
Yan Ness: Predictable, portable, intelligent.
Predictable because infrastructure behaves consistently regardless of the underlying hardware. Portable because code works across production, DR, test, edge, and cloud without modification. Intelligent because the infrastructure operating system will increasingly inform and optimize automation decisions based on actual system behavior.
That future requires moving beyond fragmented infrastructure toward unified platforms where storage, compute, networking, and protection operate as integrated services. The CX automation intelligence isn’t in the tools—it’s in the substrate that supports them.

Is Automation the New CX Enabler?
As the lines between IT performance and customer experience blur, VergeIO’s innovation underscores a decisive truth — automation is now the new CX enabler. From cloud providers to large enterprises, the ability to deploy, configure, and monitor ecosystems with uniform precision doesn’t just reduce operational fatigue; it enhances every point of user interaction.
The new VergeOS CX automation chain with Packer and Ansible support extends beyond tools — it’s a manifestation of predictable excellence. Enterprises can now standardize infrastructure behavior, ensure compliance across sites, and empower teams to automate not just faster, but smarter. For organizations steering their VMware exit strategies or scaling multi-cloud environments, this signifies a momentous step in reclaiming control and confidence.
At CXQuest, the takeaway is simple yet profound: when infrastructure operations become seamless, the customer experience becomes effortless. VergeIO is not merely building platforms — it’s engineering peace of mind into the digital foundations of tomorrow.