
Enhancing LLM Inference with Alluxio and vLLM Production Stack: A Customer Experience Perspective
Large language models (LLMs) are transforming industries with their ability to process vast amounts of data quickly. However, deploying these models efficiently remains a challenge. Slow inference speeds, high memory consumption, and complex scaling issues hinder seamless integration. To solve these problems, Alluxio and the vLLM Production Stack have joined forces. This partnership enhances LLM inference by improving performance, optimizing memory, and enabling scalability.
Why LLM Inference Needs Optimization
AI-driven applications rely on real-time responses. Customers expect fast and accurate outputs from chatbots, recommendation systems, and automation tools. However, LLMs often struggle with high latency, slow token generation, and inefficient memory usage. These limitations lead to frustrating user experiences, affecting customer satisfaction.
To address these concerns, companies seek optimized solutions that enhance inference speeds, reduce infrastructure costs, and improve overall efficiency. The collaboration between Alluxio and vLLM Production Stack provides exactly that.
How Alluxio and vLLM Improve CX
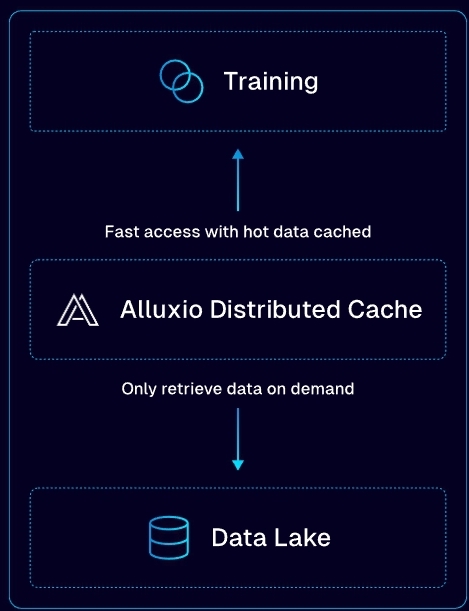
1. Faster Inference Speeds with Optimized Data Access
Waiting too long for responses frustrates customers. Slow time-to-first-token (TTFT) impacts real-time applications, making conversations feel unnatural. To improve this, Alluxio enhances data access, ensuring LLMs retrieve and process information faster.
- How does it work? Alluxio provides a distributed data orchestration layer that reduces bottlenecks in accessing model weights and datasets.
- Why does this matter? Faster data retrieval means quicker token generation, leading to near-instantaneous responses.
For customer-facing applications, speed is everything. With this integration, businesses can deliver snappier, more engaging interactions.
2. Efficient Memory Management with KV Cache Optimization
LLMs require massive amounts of memory to store and retrieve processed data. Without efficient management, memory overflows and crashes become common, leading to downtime. Alluxio’s advanced KV (key-value) cache management optimizes how LLMs store and access key-value pairs, reducing memory wastage.
- What does this mean for customers? More stable applications with fewer disruptions.
- Why is this crucial? Customers expect reliable services that don’t freeze or crash unexpectedly.
With optimized memory allocation, applications run smoothly, ensuring a frictionless customer experience.
3. Seamless Scalability Without Complexity
Scaling AI applications can be difficult. Many businesses struggle with expanding their infrastructure without disrupting ongoing services. The vLLM Production Stack simplifies this by allowing companies to scale LLM inference from a single instance to distributed deployments without modifying their application code.
- How does this help? Businesses can expand their AI capabilities effortlessly, keeping up with increasing demand.
- What’s the benefit? Customers experience consistent performance, even during high-traffic periods.
With hassle-free scaling, businesses can focus on delivering value rather than managing technical complexities.
4. Real-Time Monitoring for Proactive Performance Management
Unexpected downtimes and performance drops harm customer satisfaction. To mitigate these risks, the vLLM Production Stack provides a comprehensive observability suite, including real-time dashboards.
- What do businesses gain? Instant insights into system health, enabling proactive issue resolution.
- How does this impact CX? Reduced downtime ensures uninterrupted services, keeping customers satisfied.
By leveraging detailed monitoring tools, companies can maintain optimal performance at all times.
Customer-Centric Benefits of This Integration
1. Faster Response Times Mean Better Engagement
Slow responses lead to frustration and reduced engagement. Whether it’s a virtual assistant, content generator, or recommendation engine, customers expect instant feedback. This integration reduces latency, making AI-powered interactions feel more natural.
2. Improved Reliability Builds Trust
When AI services crash or become unresponsive, customers lose trust. Alluxio and vLLM ensure higher uptime and system stability, leading to a more dependable AI experience.
3. Efficient Scaling Supports Business Growth
As businesses expand, AI workloads increase. The ability to scale seamlessly without rewriting code saves time and effort. This flexibility allows businesses to grow without worrying about infrastructure limitations.
4. Cost-Effective Performance Enhancements
Optimized inference leads to lower computational costs. Businesses can achieve better performance without excessive hardware investments, making AI deployment more sustainable.
Industry Use Cases
E-commerce: Personalized Shopping Experiences
AI-driven recommendations enhance customer journeys. Faster inference means real-time product suggestions, leading to higher conversion rates.
Customer Support: Smarter Virtual Assistants
Reduced response times create more human-like conversations, improving customer interactions and reducing frustration.
Healthcare: Faster Diagnosis with AI Models
Medical AI systems process vast datasets. Optimized LLM inference allows quicker diagnoses and better patient care.
Financial Services: Secure and Real-Time Fraud Detection
LLMs analyze transactions for anomalies. With faster inference speeds, fraudulent activities can be detected before they cause damage.
Conclusion: The Future of AI-Powered CX
Customers demand fast, reliable, and intelligent AI services. By partnering with vLLM Production Stack, Alluxio ensures that businesses can meet and exceed these expectations. Faster inference, better memory management, seamless scalability, and real-time monitoring make this integration a game-changer.
For organizations leveraging LLMs, this collaboration is a step toward delivering world-class customer experiences.